一、爬虫
说到爬虫不得不说 python,因为我学 python 很大一部分原因是因为爬虫,爬虫之前有新闻报道,说爬虫犯法了,但不能不说爬虫是个好东西,只要我们在法律允许的范围内,合理使用爬虫就好了
而我近期学习爬虫,将学习过程记录了下来,算是我学习爬虫的一个笔记吧,我看的是北京理工大学,嵩天副教授的 python网络爬虫与信息提取 的国家精品在线开放课程,讲的十分详细,我感觉不错
二、Requests 模块
1、安装requests
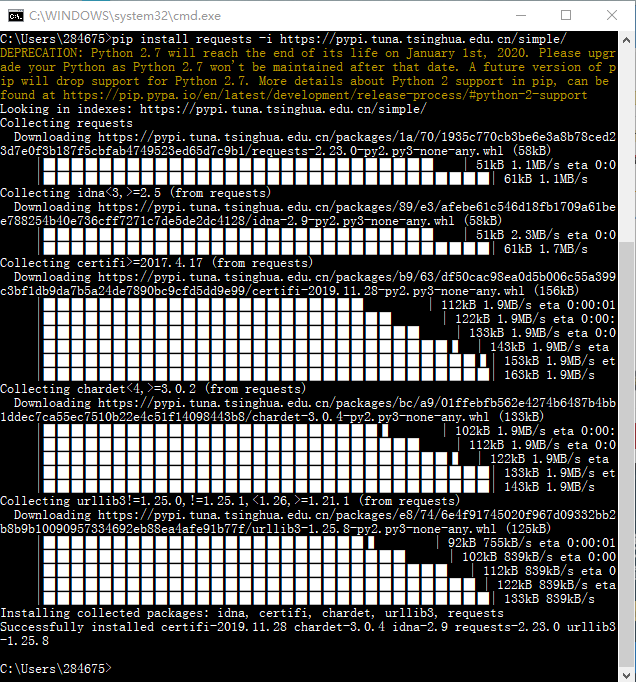
我们使用pip安装request模块,为了下载比较快,我们使用清华开源镜像库:https://pypi.tuna.tsinghua.edu.cn/simple/
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/
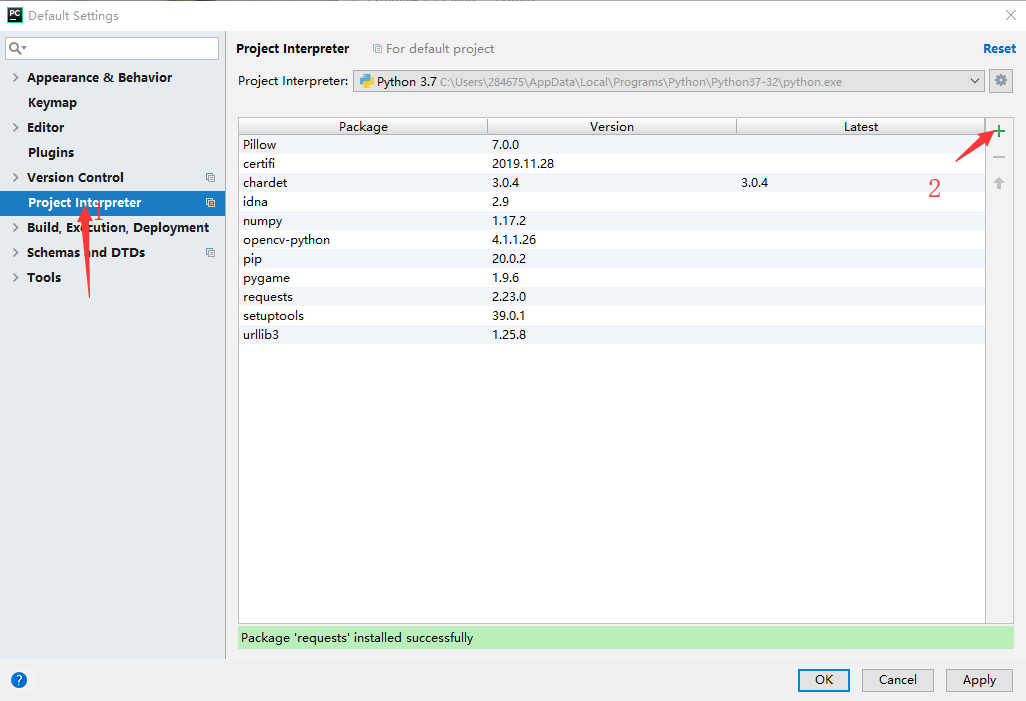
或者用pycharm打开project interpreter
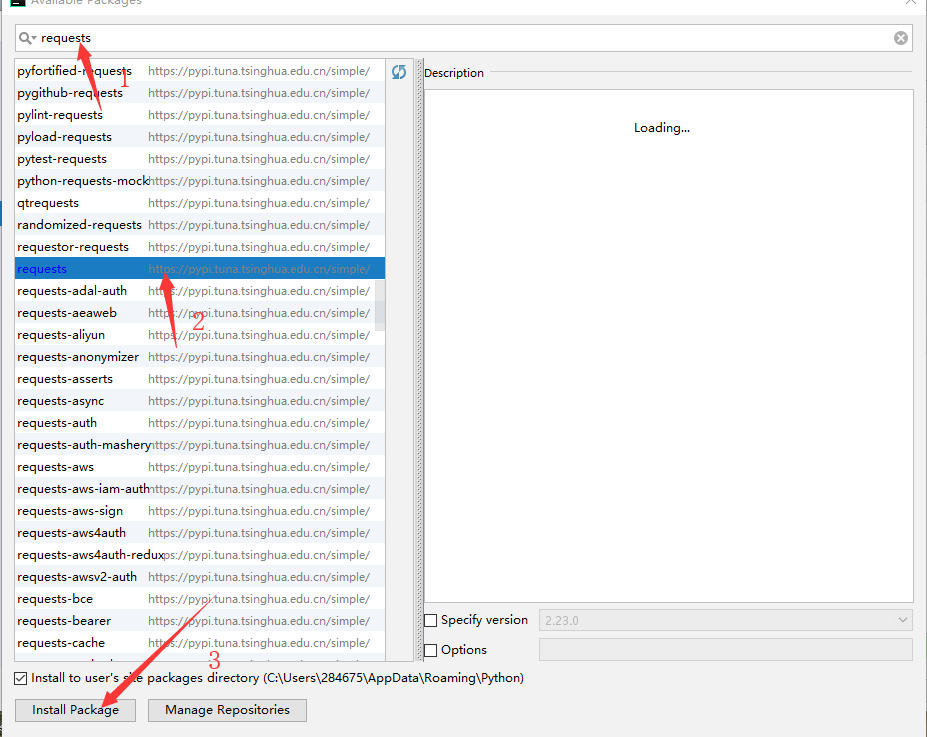
搜索requests,选中后进行安装
2、HTTP协议
HTTP:超文本传输协议,是基于“请求与响应”模式的、无状态的应用层协议,采用URL作为定位网络资源的标识
URL: 格式http://host[:port][path]
1 | * host: 合法的Internet主机域名或IP地址 |
HTTP的URL理解:
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
HTTP协议对资源的操作:
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获取该资源的头部信息 |
| POST | 请求向URL的位置资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL未知的资源 |
| PATCH | 请求局部更新URL未知的资源,即改变该处资源的部分内容 |
| DELETD | 请求删除URL位置存储的资源 |
requests 模块的主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get(url) | 获取HTML网页的主要方法,对应HTTP的GET,获取网络资源 |
| requests.head(url,get) | 获取HTML网页头部形式,对应HTTP的HEAD,以很少的流量获取资源的概要信息 |
| requests.post(url, post,date) | 向HTML网页提交POST请求,对应HTTP的POST,向服务器提交新增数据 |
| requesrs.put(url,put,date) | 向HTML网页提交PUT请求,对应HTTP的PUT,向服务器提交数据,覆盖旧的数据 |
| requests.patch() | 向HTML网页提交局部修改请求,对应HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应HTTP的DELETE |
requests 模块中的方法一一对应 http 协议对于资源的操作
3、requests模块主要方法
1 | requests.request(method,url,**kwargs) |
- method : 请求方式,对应“GET”,”POST”,”PUT”,”DELETE”,”HEAD”,PATCH”,OPTIONS”7种
- url:拟获取页面的URL链接
- **kwargs:控制访问参数,共13个
| 控制参数 | 说明 |
|---|---|
| params | 字典或者字节序列,作为参数增加到URL中 |
| data | 字典或者字节序列或文件对象,作为Request的内容 |
| headers | 字典,HTTP定制头 |
| cookies | 字典或者CookieJar,Request中的cookie |
| auth | 元组,支持HTTP认证功能 |
| files | 字典类型,传输文件 |
| timeout | 设定超时时间,秒为单位 |
| proxies | 字典类型,设定访问代理服务器,可以增加登录认证 |
| allow_redirrects | True/Flase,默认为True,重定向开关 |
| stream | True/Flase,默认为True,获取内容立即下载开关 |
| verify | True/Flase,默认为True,认证SSL证书开关 |
| cert | 本地SSL证书路径 |
| json | JSON格式的数据,作为Request的内容 |
1 | requests.get(url,params = None,**kwargs) |
- url : 拟获取页面的url连接
- params : url的额外参数,字典或字节流格式,可选
- **kwargs : 12个控制参数
1 | requests.head(url,**kwargs) |
- url :拟获取页面的url
- **kwargs:13个控制访问参数
1 | requests.post(url,data=None,json=None,**kwargs) |
- url :拟更新页面的URL
- data:字典、字节序列或文件,request的内容
- json:JSON格式的数据,request的内容
- **kwargs:11个控制访问参数
1 | requests.put(url,data=None,**kwargs) |
- url:拟更新页面的url连接
- data:字典、字节序列或文件,request的内容
- **kwargs:12个控制访问参数
1 | request.patch(url,data=None,**kwargs) |
- url:拟更新页面的URL
- data:字典,字节序列或文件,request的内容
- **kwargs:12个控制访问参数
1 | request.delete(url,**kwargs) |
- URL :拟删除页面的URL连接
- **kwargs:13个控制访问参数xs
4、request模块的 get() 方法
获取一个网页最简单的方法是使用
r = request.get(url)
给定get方法和url构造一个向服务器请求资源的request对象 ,返回包含服务器资源的Response对象,Response包含了所有资源
request.get(url,params=None,**kwargs)
- url : 拟获取页面的URL连接
- params :URL中的额外参数,字典或字节流格式,可选
- **kwargs : 12个控制访问的参数,可选
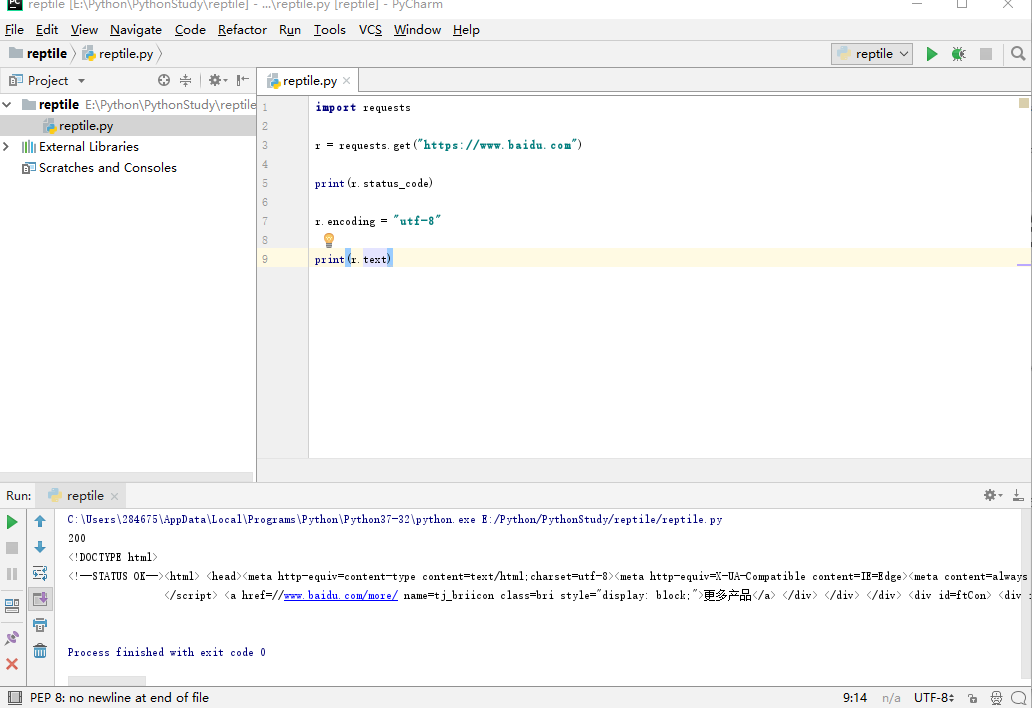
Response 对象属性:
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP 请求的返回状态,200表示连接成功,404表示连接失败 |
| r.text | HTTP 相应内容的字符形式,即,url对应的页面内容 |
| r.encoding | HTTP header 中猜测的响应内容的编码格式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP 响应内容的二进制形式 |
r.encoding:如果header中不存在charset ,则认为编码为 ISO-8859-1
r.apparent_encoding: 根据网页内容分析出的编码方式
4、爬取网页的通用代码
爬取网页的通用代码框架
1 | def getHTMLText(url): |
5、request 模块异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP 错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
理解Requests模块的异常
| 异常 | 说明 |
|---|---|
| r.raise_for_status() | 如果不是200,产生requests.HTTPError |
三、BeautifulSoup 模块
1、安装BeautifulSoup 模块
使用命令pip install beautifulsoup4安装,或者使用pycharm安装
BeautifulSoup 是解析、遍历、维护“标签树”的功能库
引用 BeautifulSoup 常用from bs4 import BeautifulSoup
2、信息标记的三种形式
信息的标记
- 标记后的信息可形成信息组织结构,增加了信息维度
- 标记后的信息可用于通信、存储或展示
- 标记的结构与信息一样具有重要价值
- 标记后的信息跟有利于程序的理解和运用
HTML(hyper text markup language) 超文本标记语言,是WWW(world wide wed)的信息组织方式,能将声音 图像 视频等超文本信息嵌入到文本信息中。HTML通过预定义的<>...</>标签形式组织不同类型的信息
信息标记的三种形式:XML、JSON、YAML
XML:XML(eXtensible Markkup Language) :扩展标记语言与HTML类似,以标签为主来构建信息表达信息的方式,如果有信息就用一对<name>...</name>来表达信息,如果没有内容可以用</name>来表示,也可以用<!-- -->来表示注释
JSON:JSON(JavaScript Object Notation):JavaScript 语言中对面向对象信息的一种表达形式,简单来讲就是有类型的键值对 key: value,来构建的信息表达方式。“key”:”value”,是有数据类型的信息,当同一个键值有多个key时,可以使用"key":["value1","value2"...],键值对可以嵌套使用"key":{"newkey":"value"}
YAML:YAML(YAML Ain’t Markup Language):采用无类型的键值对来构建信息,key: value,用缩进来表达所属关系,如:
1 | key : |
YAML 用-表示并列关系,如:
1 | key : |
YAML 用|来表示整块数据 #表示注释
三种信息标记形式的比较
XML 用<name>...</name>来表达信息,JSON用有类型的键值对来表示信息的,YAML是用无类型的键值对来表达信息的
XML:
1 | <person> |
JSON:
1 | { |
YAML:
1 | fristName: Tim |
XML:最早的通用信息标记语言,可扩展性好,但繁琐,在Internet上的信息交互于传递
JSON:信息有类型,适合程序处理(js),较XML简洁,用在移动应用云端和节点的信息通信中,没有注释,用在程序对接口的处理中
YAML:信息无类型,文本信息比例最高,可读性好,用在各类系统的配置文件中,有注释易读
3、信息提取的一般方法
第一种:完整解析信息的标记形式,再提取关键信息,XML,JSON,YAML,需要标记解析器,例如bs4库的标签树遍历,优点是信息解析准确,缺点是提取过程繁琐,速度慢
第二种:无视标记形式,直接搜索关键信息,对信息的文本利用查找函数查找就可以,优点是提取过程简单,缺点是提取结果准确性与信息内容相关,
第三种:融合方法,结合形式解析与搜索方法,提取关键信息,需要标记解析器及文本查找函数
4、BeautifulSoup解析
将获得到的网页资源进行解析,转换成容易识别的、标签类型的信息标记,为后续爬取做准备工作
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,”html.parser”) | 安装bs4 |
| lxml的HTML解析器 | BeautifulSoup(mk,”lxml”) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,”xml”) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,”html5lib”) | pip install html5lib |
基于bs4库的HTML格式化和编码
1 | soup = BeautifulSoup(f.text,"html.parser") |
prettify()将HTML的标签进行换行等处理,使得标签十分清晰,
bs4库将读入的HTML和其他字符串的编码转换为utf-8
1 | import requests |
5、BeautifulSoup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,<p>...</p>的名字是’p’,格式:<tag>.name |
| Attributes | 标签的属性,字典形式的组织,格式:<tag>:attrs |
| NavigableString | 标签内非属性字符串,<>...</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的comment类型 |
1 | import requests |
运行结果:
1 | a |
6、基于bs4模块的HTML内容遍历
标签树的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将<tag>所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类型,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
1 | soup = BeautifulSoup(f.text,"html.praser") |
1 | for child in soup.body.children: #遍历儿子标签 |
1 | for descendants in soup.body.descendants: # 遍历子孙节点 |
标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈标签 |
1 | soup = BeautifulSoup(f.text,"html.parser") |
遍历先辈标签
1 | soup = BeautifulSoup(f.text,"html.parser") |
标签树的平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前序所有平行节点标签 |
平行遍历发生在同一个父节点的各节点间,各平行标签不一定都是标签,有可能是 NavigableString
1 | soup = BeautifulSoup(f.test,"html.parser") |
标签树的平行遍历
1 | for sibling in soup.a.next_siblings: # 遍历 a 标签的下一个平行标签 |
1 | for sibiling in soup.a.previous_siblings: # 遍历 a 标签的上一个标签 |
7、基于bs4库的HTML内容查找方法
1 | soup.find_all("a") # 查找 a 标签 |
1 | import re |
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找结果
name :对标签名称的检索字符串
attrs:对标签属性值的检索字符串,可标注属性检索
recursive:是否对子孙全部检索,默认为True
string:<>...</>中字符串区域的检索字符
1 | soup.fina_all('p','course') # 查找还有course属性的P标签 |
1 | import re |
1 | soup.find_all("a",recursive = Flase) # 从soup 的根节点开始,儿子节点中没有 a 标签 |
1 | soup.find_all(string="basic pyhton") # 从soup中检索basic Pyhton |
1 | import re |
<tag>(..)等价于<tag>.find_all(..)
soup(..)等价于soup.find_all(..)
soup的find方法扩展
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,字符串类型,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,字符串类型,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,字符串类型,同.find()参数 |
1 | # 爬取最好大学网站的大学排名信息 |
输出结果:
1 | 排名 学校名称 总分 |
四、RE模块
1、正则表达式
正则表达式(regular expression regex RE):正则表达式是用来简洁表达一组字符串的表达式
1 | py+ 表示p后面有几个或多个y的字符串 |
正则表达式特点:
通用的字符串表达框架
简洁表达一组字符串的表达式
针对字符串表达“简洁”和“特征”思想的工具
判断某字符串的特征归属
正则表达式在文本处理中十分常用
- 表达文本类型的特征(病毒、入侵等)
- 同时查找或替换一组字符串
- 匹配字符串的全部或部分区域
正则表达式的使用:
编译:将符合正则表达式语法的字符串转换为正则表达式特征
正则表达式的语法:
1 | P(Y|YT|YTH|YTHON)?N |
正则表达式由字符和操作符构成
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [] | 字符集,对单个字符给出排除范围 | [abc]表示a,b,c,[a |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或非b或非c的单个字符串 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab,abc,abcc,abccc等 |
| + | 前一个字符1次或 无限次扩展 | abc+表示abc,abcc,abccc等 |
| ? | 前一个字符0次或1次 扩展 | abc?表示ab,abc |
| | | 左右表达式任意一个 | abc|def表示abc,def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc,abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在字符串结尾 |
| () | 分组标记,内部只能使用|操作符 | (abc)表示abc,(abc|def)表示abc,def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9] |
经典正则表达式实例
1 | ^[a-za-z]+$ 由26个字母组成的字符串 |
匹配IP地址的正则表达式:IP地址字符串形式的正则表达式 IP地址分4段,每段0-255,\d+.\d+.\d+.\d+
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3},这两个不精确,精确的(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}(1-9)?\d|1\d{2}|2[0-4]\d|25[0-5]
2、Re库的使用
Re库是Pyhton的标准库,主要用于字符串匹配,正则表达式是raw string类型(原生字符串类型),表示为r’text’,原生字符串类型是不包含转义符的字符串,也可以用string类型的,但更为复杂繁琐(因为有转义符)
Re库主要功能函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表形式返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
1 | re.search(pattern,string,flags=0) |
- 在一个字符串类型中搜索匹配正则表达式的第一个位置,返回match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配的字符串
- flags :正则表达式使用时的控制标记
flags正则表达式使用时常用的控制标记
| 常用标记 | 说明 |
|---|---|
| re.I re.IGNORECASE | 忽略正则表达式的大小写,[A-Z]能匹配小写字符 |
| re.M re.MULTILINE | 正则表达式中的^操作符能够将给定字符串的每行当做匹配开始 |
| re.S re.DOTALL | 正则表达式中的 . 操作符能够匹配所有中字符,默认匹配除换行外的所有字符 |
1 | import re |
1 | re.match(pattern,string,flags=0) |
- 从一个字符串的开始位置起匹配正则表达式,返回match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配的字符串
- flags :正则表达式使用时的控制标记
1 | import re |
1 | re.findall(pattern,string,flags=0) |
- 搜索字符串,以列表形式返回 全部能匹配的子串
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配的字符串
- flags :正则表达式使用时的控制标记
1 | import re |
1 | re.split(pattern,string,maxsplit=0,flags=0) |
- 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配的字符串
- maxsplit:最大分割数,剩余部分作为最后一个元素输出
- flags :正则表达式使用时的控制标记
1 | import re |
返回
1 | ['BIT','TUS',' '] |
1 | re.finditer(pattern,string,falgs=0) |
- 搜索字符串,返回一个匹配结果的迭代类型,每个迭代类型元素是match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配的字符串
- flags :正则表达式使用时的控制标记
1 | import re |
1 | re.sub(pattern,repl,string,count=0,flags=0) |
- 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
- pattern:正则表达式的字符串或原生字符串表示
- repl:替换匹配字符串的字符串
- string:待匹配的字符串
- count:匹配的最大替换次数
- flags :正则表达式使用时的控制标记
1 | import re |
返回
1 | 'BIT:zipcode TUS:zipcode' |
Re的另一种等价用法
1 | rst = re.search(r'[1-9]\d{5}','BIT 100081') #函数式用法,一次调用 |
1 | regex = re.compile(pattern,flags=0) |
- 将正则表达式的字符串形式编译成正则表达式对象
- pattern:正则表达式的字符串或原生字符串表示
- flags:正则表达式使用时的控制标记
| 函数 | 说明 |
|---|---|
| regex.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| regex.match | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| regex.findall() | 搜索字符串,以列表形式返回全部能匹配的子串 |
| regex.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| regex.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| regex.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
3、match对象类型
1 | match = rst = re.search(r'[1-9]\d{5}','BIT 100081') |
运行结果:
1 | 100081 |
match 对象属性:
| 属性 | 说明 |
|---|---|
| .string | 带匹配的文本 |
| .re | 匹配时使用的pattern对象(正则表达式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
match 对象的方法:
| 方法 | 说明 |
|---|---|
| .group() | 获取匹配后的字符串 |
| .start() | 匹配字符串在原始字符串的开始位置 |
| .end() | 匹配字符串在原始字符串的结束位置 |
| .span() | 返回(.start()),(.end()) |
1 | import re |
运行结果:
1 | 'BIT100081 TSU100084' |
4、re库的贪婪匹配和最小匹配
re库默认采用贪婪匹配,即输出匹配最长的子串
1 | match = re.search(r'PY.*N','PYANBNCNDN') |
输出结果:
1 | 'PYANBNCNDN' |
最小匹配:
1 | match = re.search(r'PY.*?N','PYANBNCNDN') |
输出结果:
1 | 'PYN' |
最小匹配操作符
| 操作符 | 说明 |
|---|---|
| *? | 前一个字符0次或无限次扩展,最小匹配 |
| +? | 前一个字符串1次或无限次扩展,最小匹配 |
| ?? | 前一个字符0次或1次扩展,最小匹配 |
| {m,n}? | 扩展前一个字符m至n次(含n),最小匹配 |
五、selenium 模块
1、安装selenium模块
使用 pip install 命令安装selenium 模块,或者在 pycharm 里面安装,安装步骤和安装 requests 模块相同
2、安装Chromedriver
Chromedriver 是谷歌出的一款无头浏览器,我可可以用 python 中的 selenium 模块调用无头浏览器,模拟认为操作浏览器
查看你浏览器的版本,下载的无头浏览器要和你的浏览器版本相对应,打开浏览器,找到 帮助->关于 Google Chrome 查看浏览器版本,下载对应的无头浏览器
下载完成后,将无头浏览器添加到你 python 的目录中,或者在调用的时候指明无头浏览器的路径
3、selenium模块使用
Chromedriver 的设置
1 | from selenium import webdriver |
- 设置chrome 二进制文件的位置
- 添加启动参数(add_argument)
- 添加扩展应用 (add_extension, add_encoded_extension)
- 添加实验性质的设置参数 (add_experimental_option)
- 设置调试器地址 (debugger_address)
使用
1 | option = webdriver.ChromeOptions() |
这样就会打开无头浏览器
Chromedriver浏览网页
1 | dr.get(url) |
这样就会通过url 打开网页
Chromedriver定位标签
- find_element_by_id() #通过id查找获取
- find_element_by_name() #通过name属性查找
- find_element_by_class_name() #通过class属性查找
- find_element_by_tag_name() #通过标签名字查抄
- find_element_by_link_text() #通过浏览器中可点击的文本查找
- find_element_by_xpath() #通过xpath表达式查找
- find_element_by_css_selector() #通过css选择器查找
1 | driver.find_element_by_id('01') #找到标签 ID 为 01 的标签 |
Chromedriver控制页面
- 设置浏览器窗口大小:driver.set_window_size(480, 800)
- 回退到上一个访问页面:driver.back()
- 前进到下一个访问页面:driver.forward()
- 退出浏览器:driver.quit()
webdriver常用操作
- click() 点击
- send_key(value) 输入值
- clear() 清空输入
- size 元素对应的大小
- text 获取对应元素的文字
1 | driver.find_element_by_id('01').click() |
webdrive中ActionChains类的鼠标动作
- perform():执行所有ActionChains中存储的所有行为
- context_click():右击
- double_click():双击
- drag_and_drop():拖动
- move_to_element():悬浮
- click_and_hold():鼠标按住不松手
- move_to_lelment():拖动到某元素
- move_by_offset(xoffset=50,yoffset=60):按坐标移动
首先我们需要定位到响应元素, 然后使用ActionChains(实例化的浏览器)中鼠标操作(带操作的元素)的各种方法
1 | from selenium.webdriver.common.action_chains import ActionChains |

